We benchmarked GPT-4.1: Here’s what we found

As AI coding assistants continue to evolve, one of the most relevant questions today is: which model provides the most helpful, precise, and actionable feedback for developers? To explore this, we ran a focused benchmark comparing GPT-4.1 and Claude 3.7 Sonnet (20250219), using a real-world task: generating code suggestions for pull requests.
Benchmark Setup
Our methodology followed a structure similar to our fine-tuning benchmark. Here’s how we approached it:
- 200 real pull requests (PR) were aggregated from a diverse set of repositories.
- For each PR, we prompted both models to generate code suggestions with the same context using this code suggestion prompt.
To evaluate responses, we used an AI judge model (o3-mini) that compared outputs and determined which was more useful and accurate. (We cross-validated with Claude and GPT-4o judges, which showed similar trends.)
Sample judge output
which_response_was_better: 1 why: "Response 1 focuses exclusively on the new code introduced in the PR and provides a precise suggestion to normalize `direction_positive` during the parallelism check. In contrast, Response 2, while offering a similar suggestion for the vector file, also adds an incorrect suggestion for the decorator in _functions.py, which is already correctly implemented in the diff." score_response1: 8 score_response2: 5
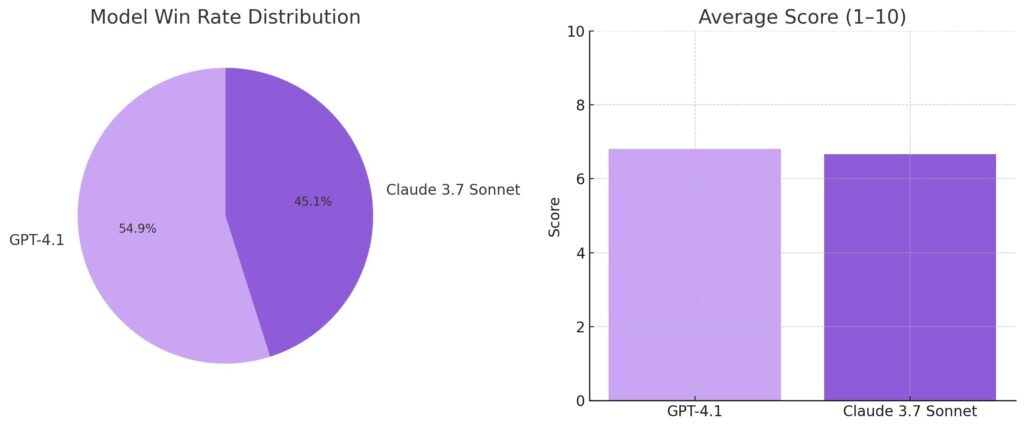
Results
Across the 200 pull requests, GPT-4.1 was judged better in 54.9% of the cases, while Claude 3.7 Sonnet came out ahead in 45.1% of comparisons. On average, GPT-4.1 received a score of 6.81 out of 10 for its suggestions, slightly outperforming Claude 3.7, which averaged 6.66.
While the margin isn’t massive, the consistent edge demonstrated by GPT-4.1 across diverse codebases and pull request scenarios highlights a meaningful advantage in real-world developer workflows.
Where GPT-4.1 outperforms: analysis of code improvement suggestions
After analyzing the dataset of code improvement suggestions, here are the key areas where GPT-4.1 demonstrates superior performance:
Better signal-to-noise ratio
GPT-4.1 avoids suggesting unnecessary changes, helping reduce noise in code reviews and limiting false positives. For example:
- GPT-4.1 correctly returns an empty list since the PR diff only renames and adjusts configuration values without introducing new bugs or issues, while the competing model invents suggestions about comment consistency that are neither clearly required nor reflected in the new code.
- GPT-4.1 correctly detects that no critical bug applies and returns an empty suggestions list, while the other model invents a duplicated key issue that does not match the diff.”
- The PR diff does not show a critical bug needing a change; GPT-4.1’s empty list aligns with instructions to only suggest fixes for critical issues, whereas the competing model invents a suggestion (changing ‘==’ to ‘===’) that is not clearly required.
More contextually relevant bug detection
GPT-4.1 accurately identifies real issues in modified code and offers suggestions that directly address the actual changes. For example:
- GPT-4.1 focuses directly on the critical issues in the Dockerfile by addressing environment variable persistence, error handling during the OpenSSL build process, and correct creation of symlinks—all of which are crucial and clearly explained.
- GPT-4.1 provides more focused and contextually relevant suggestions by targeting potential runtime issues in the new JSON parsing code and correcting duplicate properties in the equality list.
- GPT-4.1 addresses an actual potential critical error by ensuring that the positive direction vector is not a zero vector before normalization, while the competing model misinterprets the existing logic around the perpendicularity condition.
Superior Adherence to Task Requirements
GPT-4.1 follows instructions better and can identify only critical bugs when given the task, rather than stylistic or minor issues. For example:
- GPT-4.1 is more targeted in its analysis, directly highlighting the critical asynchronous handling issues in the pairing process and the risks of overlapping modal dialogs, while also ensuring proper nil-checks.
- GPT-4.1 accurately identifies critical issues by flagging the new dependency on ‘System.Web’, which could cause compatibility problems in non-.NET Framework environments, as per the task instructions.
- GPT-4.1 provides more actionable and relevant suggestions by addressing potential runtime issues via null checks and parameter validations for critical payout functionality. In contrast, the competing model focuses on areas that are either already sufficiently implemented in the diff or not directly tied to a visible bug.
This analysis shows that GPT-4.1’s superior performance stems from its ability to avoid suggesting fixes when none are needed, accurately identify real issues in modified code, and adhere more closely to task requirements by focusing on genuinely critical problems.
Takeaway
GPT-4.1 shows a promising combination of accuracy, focus, depth, and practicality in generating code suggestions for pull requests. It understands when to be silent and when to be thorough – an invaluable trait for AI tools assisting in real-world development workflows.
Qodo now supports GPT-4.1 in Qodo Gen, our IDE plugin for agentic coding and testing. As AI continues to integrate into our daily dev practices, these benchmarks help inform the tools we choose, and how we use them effectively.
You can try out GPT-4.1 in Qodo Gen in VS Code or Jetbrains.




