Comparison of Claude Sonnet 3.5, GPT-4o, o1, and Gemini 1.5 Pro for coding
For developers looking to leverage LLMs and AI-powered tools to assist them in coding tasks, there are a myriad of options available. In recent weeks we’ve seen new models from Anthropic, including Claude Sonnet 3.5, and OpenAI with new additions to the GPT family including GPT-o1-preview.With the introduction of these models—and their accessibility Qodo recently released supportfor these new models)—the question is: which model is best for which task?
For me, choosing the right AI model isn’t just about technical fit; it’s about optimizing my workflow and playing to each model’s strengths to keep my projects efficient and high quality.
This blog shares my learnings and aims to help developers navigate these new LLMs with opinionated guidance on key considerations and model capabilities. Here’s a short summary of my conclusions:
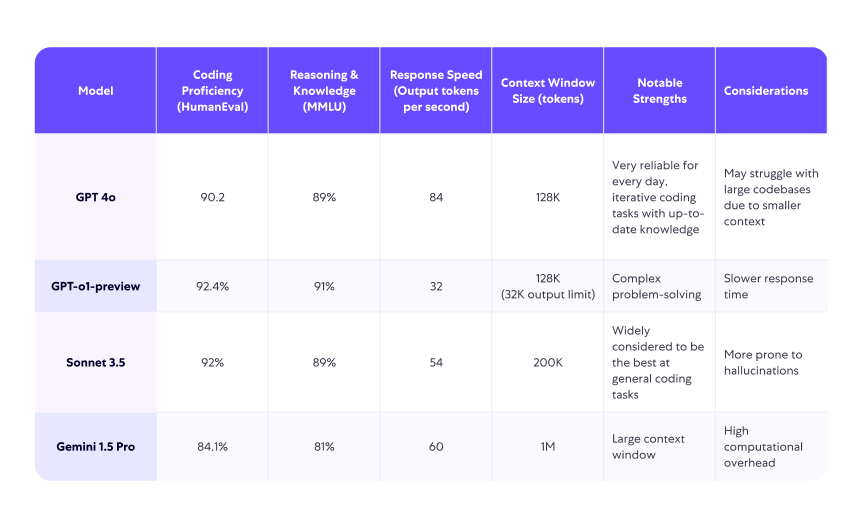
- Claude Sonnet 3.5: My go-to for everyday coding tasks with excellent flexibility and speed
- GPT-o1-preview: Ideal for planning, difficult debugging, and deep reasoning about code
- GPT-4o: Reliable for everyday, iterative coding tasks requiring up-to-date knowledge
- Gemini 1.5 Pro: Best suited for tasks that need the whole project in context, such as large-scale refactoring or generating project-wide documentation
What are the considerations to account for when choosing a model?
When I select an AI model for a coding task, I aim to align the model’s capabilities with the project’s specific needs, from speed and accuracy to reasoning ability and context handling. Here’s a closer look at the key considerations that guide me to the most suitable choice
Task Complexity
The complexity of a coding task directly impacts the level of reasoning required from an AI model. Choosing the right model for the job depends on whether the task demands simple code generation or complex, multi-layered problem-solving
Simple Tasks: For straightforward coding needs, like generating basic functions, performing syntax conversions, or creating utility scripts, faster models with core code knowledge are typically sufficient. These models can quickly handle boilerplate code without requiring advanced reasoning, making them ideal for tasks such as basic API calls, converting data between common formats, and generating function templates.
Complex Tasks: For more intricate coding challenges, such handling data processing pipelines, or developing recommendation engines, selecting a model with strong reasoning capabilities is beneficial. Such models are better equipped to handle the nuances of complex logic and can generate more precise, context-aware solutions
Response Spee
Response speed, or latency, is a critical factor in coding workflows, as it impacts how smoothly developers can transition between tasks and incorporate AI-generated suggestions without interruptio
Prioritizing Speed: In scenarios where rapid output is required, such as auto-complete and in-line code suggesting, models that offer faster responses are more ideal. This speed can keep development workflows smooth, especially when dealing with frequent, small requests
Willing to wait for quality: For tasks where accuracy and depth are more important than immediacy—such as generating complex functions, analyzing large blocks of code, or creating comprehensive test suites—models with slower response times but higher accuracy may be preferable. In these cases, the slight delay is justified by the higher quality of the output
Context Window Siz
The context window size is the maximum amount of input (measured in tokens) that a model can process at once, which determines how much information it can “remember” and reference in a single task
Large Context Requirements: For tasks that require processing extensive input or maintaining context across multiple parts of a codebase, a model with a large context window is advantageous. This allows the model to retain and work with more information, making it especially useful for use cases such as refactoring an entire codebase, system-wide migrations or documenting large, complex projects.
Smaller Context Needs: If your task doesn’t need a large amount of context, for instance writing individual functions or generating isolated unit tests, opting for a model with a smaller context window but high reasoning ability can be efficient. For most typical coding tasks that don’t require analyzing an entire project in one go, a smaller context window is generally sufficient and can even enhance the model’s focus on the immediate task
Creativity vs. Rigidity
In the current landscape of AI models, hallucinations—where a model unintentionally generates incorrect or misleading information—are an important factor to consider, especially in coding tasks that require a high level of accuracy
Accuracy-Dependent Tasks: When error-free code is crucial, selecting a model that minimizes hallucinations is essential. Tasks like implementing security-sensitive logic, performing precise data transformations, or building foundational infrastructure code (e.g., authentication modules, API integrations) demand high accuracy. In these scenarios, errors or inconsistencies can lead to vulnerabilities, data loss, or unexpected system behavior, so a model which has a reputation for reliability and reduced hallucination rates, is preferable
Creative Code Manipulation: If the task involves code refactoring or testing variations in code structure, a model which can manipulate code well but may occasionally hallucinate, can still be valuable. Such hallucinations are less impactful in non-critical, exploratory tasks where variations in the code are acceptable
Up-to-Date Knowledg
Consider how “up-to-date” the model is—how current its training data is with recent libraries, frameworks, and coding practices? A model trained with more recent data will be better suited for handling tasks that rely on the latest advancements
Recent Information Needs: Certain tasks, like using new libraries or frameworks, benefit from a model that’s up-to-date with the latest information about new releases. Some models are more regularly updated, making them more suitable for tasks that involve recent advancements
General Knowledge Tasks: For tasks that don’t rely on the most current programming techniques, other models with high reasoning capabilities can suffice. Their depth of understanding and general coding expertise can still deliver excellent results, even if their knowledge isn’t cutting-edge
Understanding Model Capabilities and Use Case
Different AI models come with varying strengths, weaknesses, and optimal use cases. Understanding these can help you select the model that best aligns with your task requirements
GPT-o1-preview: deeper reasoning
OpenAI GPT-o1-preview model stands out as one of the most capable options for complex, logic-intensive coding tasks where accuracy and deep reasoning are essential. Unlike faster models suited for quick snippets, GPT-o1-preview takes more time to think through tasks and can better handle multi-step logic.
Best For:
- Complex, multi-step tasks that go beyond standard function generation
- Large-scale projects requiring robust, contextually-aware code
- Projects where precision is prioritized over immediate outpu
Benefits:
- Produces high-quality, logically consistent code
- Handles complex dependencies
Disadvantages:
- Speed response times can be slower which can affect workflows that require instant feedback or quick iteration
Example Use Cases:
- Generating comprehensive test suites
- Code migrations between framework
- Plan a task with complex dependencies
GPT-4o: everyday coding tasks
GPT-4o model is designed to be an efficient, reliable assistant for general-purpose coding needs. It performs well in scenarios where speed and accuracy are important but does not focus on overly complex logic or multi-layered problem-solving. With its balanced approach to performance and usability, GPT-4o is a practical choice for programmers handling routine coding activities
Best for:
- Everyday, iterative coding tasks where a balance of accuracy and speed is importan
- Tasks that require a lightweight, context-aware model
Benefits:
- Faster response times compared to more complex model
- Delivers consistent accuracy across general coding task
- Handles context-awareness well for a wide range of task
- Moderately complex problem solving without excessive processing time
- Up-to-date knowledgebase including recent libraries, framework and coding best practices.
Disadvantages:
- Limited in complex reasoning and may struggle with tasks that require deeper reasoning
- Context window constraints make it efficient for smaller tasks, but 4o may have difficulty maintaining context in projects that require understanding of larger codebases or multi-step workflows
Example Uses:
- Adding docstring
- Debugging syntax error
- Formatting dat
- Basic refactoring
Claude Sonnet 3.5
Since its release and benchmarking, Claude Sonnet 3.5 has been widely recognized as one of the best models for coding, particularly excelling in code manipulation and refactoring. It’s highly versatile, handling both routine coding tasks as well as moderately complex challenges. While it may not reach the depth of reasoning that GPT-o1-preview offers, Sonnet 3.5 can be very effective in scenarios where flexibility, creativity, and speed are key.
A key advantage of Sonnet 3.5 is its up-to-date knowledge of the latest programming practices, libraries, and frameworks. With training data current as of April 2024, it provides developers with reliable and relevant support for modern coding need
Best for:
- General coding and everyday tasks
- Refactoring, restructuring and optimizing code
- Moderately complex coding challenges
- Debugging and quality improvements
Benefits:
- Quick response times
- Well-rounded solution for various coding task
- Efficient for in-line comments and autocomplet
Disadvantages
- Prone to hallucinations more than other models
- Less adept at complex, multi-step reasoning compared to GPT-o1-previe
- Limited context window can be a constraint for tasks that require a comprehensive understanding of large codebase
Example uses:
- Generating utility functions
- Handling data parsing
Gemini 1.5 Pro
Gemini 1.5 Pro is designed with an exceptionally large context window—2 million tokens— making it particularly effective for coding tasks that require processing extensive input or maintaining a coherent understanding across multiple parts of a codebase
Best for:
- Projects with large codebases
Benefits:
- Large context window
Disadvantages
- Higher computational overhead
- Complexity managing context limits to ensure input remains relevant and focuse
Example uses:
- Generating project-wide documentation
With these insights into the strengths and use cases of the latest LLMs, you can make practical choices suited to you specific needs. Try these models today on Qodo to see how they can support your coding workflow.


