RAG for a Codebase with 10k Repos
We’ve seen plenty of cool generative AI coding demos lately. Some would even make you think an industrious AI agent is crushing Upwork jobs as we speak. Be that as it may, Upwork ninjas are no match for a real-life enterprise codebase with thousands of repos and millions of lines of (mostly legacy) code. For enterprise developers looking to adopt generative AI, contextual awareness is key. This is where Retrieval Augmented Generation (RAG) comes into play, however implementing RAG with large code bases has unique challenges.
One of the foremost obstacles with using RAG at the enterprise level is scalability. RAG models must contend with the sheer volume of data and navigate architectural complexities across different repositories, making contextual understanding difficult to achieve. In this blog, I’ll share how qodo (formerly Codium) approached RAG to bridge the gap between LLMs with limited context windows and large, complex code bases while building a generative AI coding platform that puts code quality and integrity first.
Applying RAG to Large-Scale Code Repositories
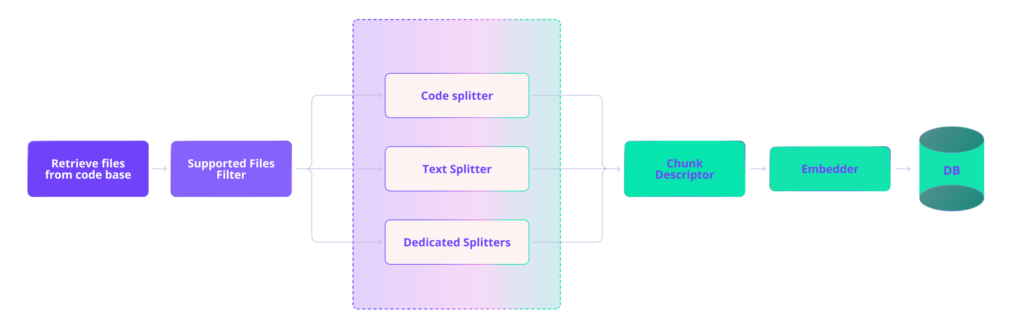
RAG can be roughly divided into two parts: indexing the knowledge base (codebase in our case) and retrieval. With RAG for a production codebase that’s constantly changing, indexing isn’t a one-time or periodic job. There needs to be a robust pipeline for continuously maintaining a fresh index.
The diagram below illustrates our ingest pipeline where files are routed to the appropriate splitter for chunking, chunks are enhanced with natural language descriptions, and vector embeddings are generated for each chunk before they’re stored in a vector DB.
Chunking
Chunking is relatively simple for natural language text — paragraphs (and sentences) provide obvious boundary points for creating semantically meaningful segments. However, naive chunking methods struggle with accurately delineating meaningful segments of code, leading to issues with boundary definition and the inclusion of irrelevant or incomplete information. We’ve seen that providing invalid or incomplete code segments to an LLM can actually hurt performance and increase hallucinations, rather than helping.
The team at Sweep AI published a great blog post last year detailing their strategies for chunking code. They open-sourced their method of using a concrete syntax tree (CST) parser to create cohesive chunks and their algorithm has since been adopted by LlamaIndex.
This was our starting point but we encountered some issues with their approach:
- Despite the improvements, the chunks still weren’t always complete, sometimes missing crucial context like import statements or class definitions.
- Hard limits on embeddable chunk size didn’t always allow for capturing the full context of larger code structures.
- The approach didn’t account for the unique challenges of enterprise-scale codebases.
To address these issues, we developed several strategies:
Intelligent Chunking Strategies
Sweep AI implemented chunking using static analysis, which is a huge improvement on previous methods. But their approach isn’t optimal in scenarios where the current node surpasses the token limit and begins splitting its children into chunks without considering the context. This can lead to breaking chunks in the middle of methods or if statements (e.g., ‘if’ in one chunk and ‘else’ in another).
To mitigate this, we use language-specific static analysis to recursively divide nodes into smaller chunks and perform retroactive processing to re-add any critical context that was removed. This allows us to create chunks that respect the structure of the code, keeping related elements together.
from utilities import format_complex
class ComplexNumber:
def __init__(self, real, imag):
self.real = real
self.imag = imag
def modulus(self):
return math.sqrt(self.real**2 + self.imag**2)
def add(self, other):
return ComplexNumber(self.real + other.real, self.imag + other.imag)
def multiply(self, other):
new_real = self.real * other.real - self.imag * other.imag
new_imag = self.real * other.imag + self.imag * other.real
return ComplexNumber(new_real, new_imag)
def __str__(self):
return format_complex(self.real, self.imag)
Naive chunking:
def __str__(self):
return format_complex(self.real, self.imag)
Our chunking:
from utilities import format_complex
class ComplexNumber:
def __init__(self, real, imag):
self.real = real
self.imag = imag
# …
def __str__(self):
return format_complex(self.real, self.imag)
Our chunker keeps critical context together with the class method, including any relevant imports as well as the class definition and init method, ensuring that the AI model has all the information it needs to understand and work with this code.
Maintaining Context in Chunks
We’ve found that embedding smaller chunks generally leads to better performance. Ideally, you want to have the smallest possible chunk that contains the relevant context — anything irrelevant that’s included dilutes the semantic meaning of the embedding.
We aim for chunks to be as small as possible and set a limit around 500 characters. Large classes or complex code structures often exceed this limit, leading to incomplete or fragmented code representations.
Therefore, we developed a system that allows for flexible chunk sizes and ensures that critical context, such as class definitions and import statements, are included in relevant chunks.
For a large class, we might create an embedding and index individual methods separately but include the class definition and relevant imports with each method chunk. This way, when a specific method is retrieved, the AI model has the full context needed to understand and work with that method.
Special Handling for Different File Types
Different file types (e.g., code files, configuration files, documentation) require different chunking strategies to maintain their semantic structure.
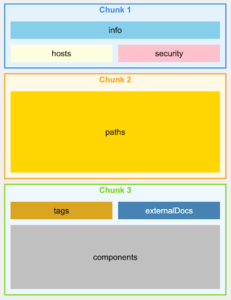
We implemented specialized chunking strategies for various file types, with particular attention to files like OpenAPI/Swagger specifications that have a complex, interconnected structure.
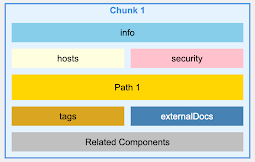
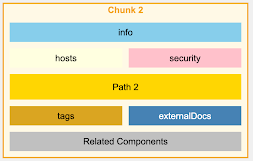
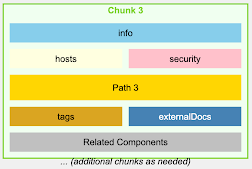
For an OpenAPI file, instead of chunking by lines or characters, we chunk by endpoints, ensuring that each chunk contains all the information for a specific API endpoint, including its parameters, responses, and security definitions.
OpenAPI v3.0 – Naive Chunking
OpenAPI v3.0 – Intelligent Chunking
Enhancing Embeddings with Natural Language Descriptions
Code embeddings often don’t capture the semantic meaning of code, especially for natural language queries.
We use LLMs to generate natural language descriptions for each code chunk. These descriptions are then embedded alongside the code, enhancing our ability to retrieve relevant code for natural language queries.
For the map_finish_reasonfunction shown earlier:
```python
# What is this?
## Helper utilities
def map_finish_reason( finish_reason: str,):
# openai supports 5 stop sequences - 'stop', 'length', 'function_call', 'content_filter', 'null'
# anthropic mapping
if finish_reason == "stop_sequence":
return "stop"
# cohere mapping - https://docs.cohere.com/reference/generate
elif finish_reason == "COMPLETE":
return "stop"
elif finish_reason == "MAX_TOKENS": # cohere + vertex ai
return "length"
elif finish_reason == "ERROR_TOXIC":
return "content_filter"
elif (
finish_reason == "ERROR"
): # openai currently doesn't support an 'error' finish reason
return "stop"
# huggingface mapping https://huggingface.github.io/text-generation-inference/#/Text%20Generation%20Inference/generate_stream
elif finish_reason == "eos_token" or finish_reason == "stop_sequence":
return "stop"
elif (
finish_reason == "FINISH_REASON_UNSPECIFIED" or finish_reason == "STOP"
): # vertex ai - got from running `print(dir(response_obj.candidates[0].finish_reason))`: ['FINISH_REASON_UNSPECIFIED', 'MAX_TOKENS', 'OTHER', 'RECITATION', 'SAFETY', 'STOP',]
return "stop"
elif finish_reason == "SAFETY" or finish_reason == "RECITATION": # vertex ai
return "content_filter"
elif finish_reason == "STOP": # vertex ai
return "stop"
elif finish_reason == "end_turn" or finish_reason == "stop_sequence": # anthropic
return "stop"
elif finish_reason == "max_tokens": # anthropic
return "length"
elif finish_reason == "tool_use": # anthropic
return "tool_calls"
elif finish_reason == "content_filtered":
return "content_filter"
return finish_reason
We might generate a description like:
“Python function that standardizes finish reasons from various AI platforms, mapping platform-specific reasons to common terms like ‘stop’, ‘length’, and ‘content_filter’.”
This description is then embedded along with the code, improving retrieval for queries like “how to normalize AI completion statuses across different platforms”. This approach aims to address the gap in current embedding models, which are not code-oriented and lack effective translation between natural language and code
Advanced Retrieval and Ranking
Simple vector similarity search often retrieves irrelevant or out-of-context code snippets, especially in large, diverse codebases with millions of indexed chunks.
We implemented a two-stage retrieval process. First, we perform an initial retrieval from our vector store. Then, we use an LLM to filter and rank the results based on their relevance to the specific task or query.
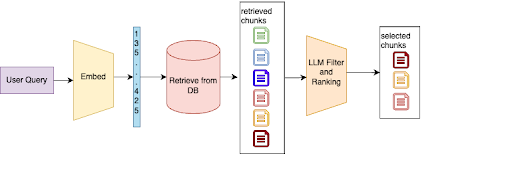
If a developer queries “how to handle API rate limiting”, our system might first retrieve several code snippets related to API calls and error handling. The LLM then analyzes these snippets in the context of the query, ranking higher those that specifically deal with rate limiting logic and discarding irrelevant results.
Scaling RAG for Enterprise Repositories
As the number of repositories grows into the thousands, retrieval becomes noisy and inefficient if searching across all repos for every query.
We’re developing repo-level filtering strategies to narrow down the search space before diving into individual code chunks. This includes the concept of “golden repos” — allowing an organization to designate specific repositories that align with best practices and contain well-organized code.
For a query about a specific microservice architecture pattern, our system might first identify the top 5-10 repositories most likely to contain relevant information based on metadata and high-level content analysis. It then performs the detailed code search within these repositories, significantly reducing noise and improving relevance.
RAG Benchmarking and Evaluation
Evaluating the performance of RAG systems for code is challenging due to the lack of standardized benchmarks.
We’ve developed a multi-faceted evaluation approach that combines automated metrics with real-world usage data from our enterprise clients.
We use a combination of relevance scoring (how often developers actually use the retrieved code snippets), accuracy metrics (for code completion tasks), and efficiency measurements (response time, resource usage). We also collaborate closely with our enterprise clients to gather feedback and real-world performance data.
Conclusion
Implementing RAG for massive enterprise codebases presents unique challenges that go beyond typical RAG applications. By focusing on intelligent chunking, enhanced embeddings, advanced retrieval techniques, and scalable architectures, we’ve developed a system that can effectively navigate and leverage the vast knowledge contained in enterprise-scale codebases.
As we continue to refine our approach, we’re excited about the potential for RAG to revolutionize how developers interact with large, complex codebases. We believe that these techniques will not only boost productivity but also improve code quality and consistency across large organizations.