Equivalence Partitioning
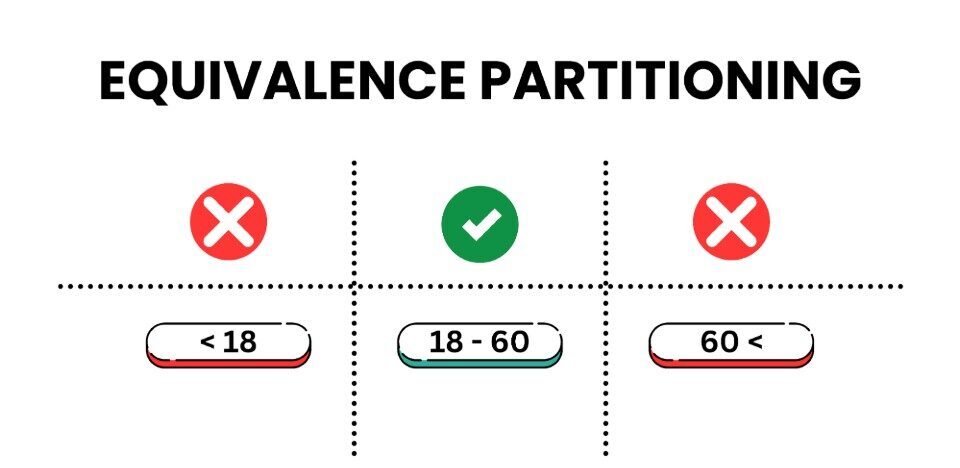
One of the most common black-box testing techniques used in software testing is equivalence partitioning. This involves grouping inputs into distinct groups to which a software application is expected to react similarly. These grouped inputs can help a tester cover more scenarios with fewer test cases, optimizing both time and resources.
The core principle of equivalence partitioning is straightforward: if one input from a defined equivalence class behaves correctly, all other inputs within that class are expected to behave similarly.
Definition of Equivalence Classes
Equivalence classes are groups of input values that share common characteristics and are treated identically by the system. Each class must be exclusive, meaning there should be no overlap between classes.
Example: Consider a numeric input field for age:
- Valid class: Ages from 18 to 60 (e.g., 25)
- Invalid class: Negative ages (e.g., -5)
- Out-of-range class: Ages below 18 or above 60 (e.g., 10 or 70)
Benefits of Equivalence Partitioning
1. Reduced Test Cases
By grouping inputs or outputs into equivalence classes with similar behavior, testers can select a representative value from each class for testing.
For example, a login form might require users to input a password between 8 and 16 characters. Without equivalence class partitioning, testers might attempt:
- 1, 2, 3, 4, 5, 6, 7, 8, 9, … 16, 17, 18, 19, and 20-character passwords.
With equivalence partitioning, testers can reduce test cases while ensuring edge conditions are tested:
- Valid: 8-16 characters (e.g., test with a password of 12 characters).
- Invalid: Fewer than 8 characters (e.g., test with 4 characters).
- Invalid: More than 16 characters (e.g., test with 18 characters).
This reduces the number of test cases from 20 to just three, saving time and ensuring sufficient coverage.
2. Early Defect Detection
By focusing on critical values within each equivalence class partitioning, equivalence partitioning helps uncover errors earlier in the testing cycle.
Consider a mobile banking app that calculates loan interest rates based on credit scores:
- Poor credit: 0-300
- Average credit: 301-700
- Good credit: 701-850
Testing each equivalence class reveals:
- A bug where users with a score of 701 are mistakenly classified under “Average” and charged higher interest.
- This error is caught early because the critical boundary value of 701 is tested.
3. Test Case Reusability
Once equivalence classes are established, these definitions can be leveraged to create additional test cases in future testing cycles.
Consider a shopping cart system that calculates shipping fees based on order weight:
- Free shipping: 0-1 kg
- Standard shipping: 1.1-5 kg
- Heavy item shipping: 5.1-20 kg
Equivalence classes defined during initial testing (e.g., weights of 0.5 kg, 3 kg, and 10 kg) can be reused when:
- Adding international shipping rates in a future project phase.
- Testing new promotions, like “free shipping for orders over $50.”
Limitations of Equivalence Partitioning
While equivalence class testing offers many advantages, it’s important to acknowledge its limitations to ensure comprehensive testing and maintain software quality:
1. Overlooking Edge Cases
Because equivalence partitioning focuses on representative values within defined partitions, outliers may escape detection, leading to undetected bugs and potential software quality issues.
Consider a mobile app that requires users to input their age. The valid range is 18-65. Using equivalence partitioning, testers can create partitions:
- Valid input: 18-65 (e.g., test with 25, 50)
- Invalid input: Below 18 (e.g., test with 10) and above 65 (e.g., test with 70).
Here, the input values 17 and 66 (just outside the valid range) might not be tested. These could trigger unexpected behaviors, such as crashes or incorrect error messages, exposing the app to bugs during production. However, by combining equivalence partitioning and boundary value analysis, testers can overcome this issue.
2. Uniform Behavior Assumption
Equivalence partitioning operates under the assumption that all data points within a partition exhibit uniform behavior.
Consider an e-commerce website that allows customers to apply coupon codes. The equivalence classes include:
- Valid codes (e.g., DISCOUNT10)
- Invalid codes (e.g., INVALIDCODE)
Equivalence partitioning assumes all valid codes behave the same. However, some valid codes might apply discounts differently (e.g., apply 15% instead of 10%).
3. Complexity in Defining Classes
Identifying and defining appropriate equivalence classes can be a complex task, particularly in large or intricate systems.
For example, a financial system calculates tax based on income levels:
- Low-income: $0-$20,000 (10% tax)
- Middle-income: $20,001-$50,000 (20% tax)
- High-income: $50,001+ (30% tax)
Defining equivalence classes becomes tricky if:
- Special cases exist, such as exemptions for certain professions.
- The tax rate changes dynamically based on additional factors like location or marital status.
Best Practices for Defining Classes
To maximize the effectiveness of equivalence partitioning, testers should adhere to several best practices:
- Consistency: Ensure all inputs in an equivalence class testing can detect similar conditions within the system.
- Representative selection: If a defect is found in one test case from a class, it’s likely others will reveal similar issues.
- Subjectivity awareness: Recognize that definitions may vary based on interpretations of software requirements.
Wrapping Up
Equivalence partitioning remains an essential component in modern software testing. Optimizing test case design and improving resource allocation contribute significantly to higher software quality and user satisfaction. While it is vital to recognize its limitations, integrating equivalence partitioning with other methodologies like boundary value analysis ensures comprehensive coverage and effective identification of potential defects. As software development continues to evolve, so will the strategies employed to ensure reliable performance across diverse applications.

